Overview
Windows network controller (WNC) is an SDN controller built for the next version of Windows Server. It is designed as a scalable and highly reliable distributed application to program physical and virtual elements of a datacenter, to provide autonomous datacenter network management. The north pole of WNC is to provide autonomous datacenter network management such that human intervention is needed only when there is a hardware failure.
WNC consists of a northbound API layer that allows application to provision various services provided by WNC. WNC decomposes these provisioning requests into various device specific settings and uses southbound APIs to program those devices. These devices can be switch, routers, gateways, load balancers, virtual switches and more.
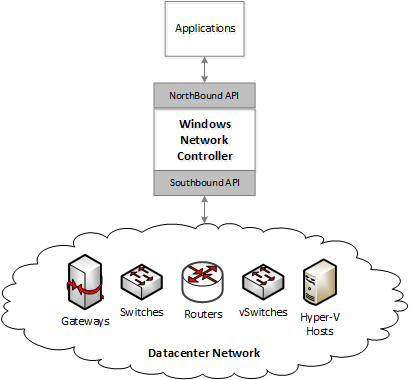
Architecture
WNC is a distributed application built using services oriented architecture. It consists of many function specific services that work together to manage the overall datacenter network. It is built upon Windows Fabric, a Microsoft technology to create highly reliable, distributed and scalable applications. There is limited public information about Windows Fabric, but you can read more about it, here and here. Using Windows Fabric, it is possible to create a cluster of machines (referred as nodes). Windows Fabric aware applications running on these nodes can failover from one node to another in the event of a failure. There can be two types of applications in Windows Fabric, stateful and stateless application. A stateful application is one that has persistent data. Windows Fabric provides state replication capabilities such that the persistent state of application is replicated to multiple nodes. This ensures that in the event of failover, the persistent state of the application is readily available without requiring use of a separate centralized database. Figure below shows the high level architecture of WNC.
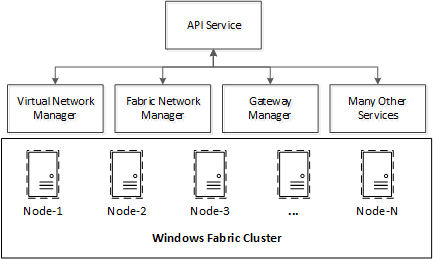
As shown above, WNC consists of multiple services. These services are function specific and each service is responsible for doing a part of the network management. For example, virtual network manager manages virtual networks created using network virtualization technologies. Similarly, gateway manager manages gateways that allow access to network outside of a virtual network.
The API service is a special WNC service that implements the HTTP endpoint and northbound REST API. All requests from applications to WNC are first received by the API service. API service then saves the requests and returns an operation id to the clients that client can use to check the status of the requested operation. After that, API service carries out the requested operation asynchronously by talking to one or more function specific service and updates the status of the operation at the end.
One important point to note here is that, the scalability boundary is at service level i.e. while different services can run on different nodes, a single service can only be active on a single node at a time. In other words, the active instance of virtual network manager service handles all virtual networks. This has proven to be sufficient since each service has specific responsibility and thereby doesn’t become a bottleneck. It is possible, in future, to be extended this to allow a single service to scale out. For example, a scaled out virtual network manager can have multiple active instances, and each instance can handle a different set of virtual networks.
Common Framework
All WNC services are built upon a common framework (referred as WNC framework) to provide consistency in service behavior such as diagnostics, performance counters, inter-service communication, southbound communication to network devices, failover, persistence etc. This common framework, not only provides consistent service behavior, it also makes it easy to develop new services.
WNC services may need to talk to each other to carry out a requested operation. This inter-service communication is provided using windows communication foundation (or WCF). A helper communication library is provided in the common framework to abstract various services from the underlying mechanics. For example, in a highly available system, a service may be running on any of the node in the cluster at any given time (as it can failover from one node to another). The framework API provides wrappers such that services don’t have to have this knowledge. Framework internally uses Windows Fabric to first locates the node hosting the target service and then creates a WCF connection to the target service on that node.
This may bring up a question i.e. if API service fails over from one node to another, how does the client find out the location of the service to connect back to it via HTTP. This is challenging because client applications can be written in any language (since we provide standard HTTP based REST interface). It is not possible to expect every client application to either use WNC framework or be aware of service to node mapping. A client application can simply be a web browser that is used to issue REST requests. To solve this problem, a concept of floating IP is created. The API service is assigned a well-known floating IP and the floating IP is programmed on whichever node the API service is active. This allows unmodified REST clients to communicate with WNC via a well-known IP address.
WNC framework provides a consistent view of devices, that are being managed by WNC, to services. This allows a uniform identification and communication with devices under the purview of WNC. It also makes it easy to diagnostics across WNC and correlate data that is generated on a device but consumed by services.
WNC framework also provides device abstractions to make it easier to program heterogeneous devices providing same capabilities. As an example, if there are two different types of switches in the network, that provide same capability but use different protocols for configuration e.g. let us say one uses OMI and other uses some custom vendor specific protocol, then using device abstraction, it is possible to abstract the common functionality. This keeps the service code clean and free of if conditions for different types of devices.
Idempotent Operations and Goal State
In any system, it is possible for an application to fail due to programming errors. It is also possible for the operating system, hosting the application to fail e.g. due to power outage, hardware issues or even programming errors. There can also be network errors that prevent inter-service communication etc.
It is extremely important that such errors neither result in data corruption nor resource leaks. It is also highly desirable to minimize the impact of such failures on the user experience.
Let us take an example for resource leak. Let us say one service (A) running on Node-1, calls another service (B) running on Node-2, to allocate a resource. Service B successfully allocates the resource, but before it can return the result to service A, the network communication fails or service B crashes or Node-2 crashes. In this case how does service A knows that its requested allocation was made? You might have seen this problem in many websites that asks you not to press a button again or refresh again as that can result in duplicate orders (bad websites).
In an autonomous environment of WNC such failures are not human manageable. So how do we prevent such resource leaks? By requiring that all inter-service communication between various services uses idempotent operations. So in this example, service A would first allocate an operation id (usually a UUID). It would then send the allocation request to service B along with the UUID. Service B would only do an allocation if an allocation for that UUID is not already done. If the allocation is already done, then service B just returns the result from the already allocated data.
If you are with me so far, then you may ask, what happens if service A itself crashes after it sent the request to service B. How would it know that it sent an allocation request etc.? This is where the concept of goal state kicks in. Each service must first create a goal state. Goal state is a list of operations that it would carry out and operation ids of those. It must then commit this to persistent storage (the atomic commit is provided by Windows Fabric). After committing to persistent store, service can run this goal state. Running this goal state is trivial because each operation is idempotent so there is no side-effect of running the same operation multiple times. For example, if a service crashes after running the partial goal state, another instance of the service on a different node would become active. This newly active service can simply look rerun the pending goal states in the persistent store from the start. There is no need to track partial goal state completions because all operations in the goal state are idempotent.
This goal state mechanism is used extensively not only for inter-service communication, but even for device configuration. This ensures that if a device state goes out of sync, a periodic goal state driver automatically corrects the state on next run. This makes the overall network highly reliable as each entity will run the goal state and bring the system to the desired state, across intermittent or even prolonged failures.
This is all I have for today, hopefully I would get a chance to get back to the topic of interrupts in my next post and talk about interrupt virtualization.
This posting is provided “AS IS” with no warranties and confers no rights.